instagramのAPIって結局何ができるのか
instagramには執筆時点でbasic display apiとgraph apiの二種類のAPIが存在する。デートスポットの情報を自分に代わって収集してくれるアプリを作成する中でinstagramのAPIでできること、できないことが分かったので整理しておく。
■instagram basic display api(基本表示API)
ビジネスアカウント(やクリエーターアカウント)、消費者アカウント(一般のアカウントのこと)問わず、認証が完了したユーザ自身が投稿した画像やcaption(投稿の際に記載する文字)の情報を取得できる。
ユーザごとにアクセストークンが紐づく形であり、アクセストークンベースで取得を行うため、認証が完了したユーザがフォローしているユーザの投稿等は取得不可。
※例えばAさんが芸能人のBさんをフォローしており、Aさんのアクセストークンを取得してAさんのタイムラインに流れている投稿を取得するということはできない。あくまでAさん自身が投稿した情報にしかアクセスできない。
つまり取得したいユーザには逐一認証してもらう必要があるという何とも不便な仕様である。
※アプリのステータスがライブ・開発に問わず共通である。
またハッシュタグ検索もできない。
利用にはfacebook開発者アカウントの登録、アプリの登録が必要。下記公式ドキュメントに従って行うのが最もわかりやすい。
https://developers.facebook.com/docs/instagram-basic-display-api
■instagram graph api(グラフAPI)
ビジネスアカウント(やクリエーターアカウント)に限るが、ユーザ自身が投稿した画像やcaption(投稿の際に記載する文字)の情報をbasic diplay apiのように取得できる。
またinstagramの通常のアプリで行うようなハッシュタグの文言で検索をかけることができ、自身がフォローしているかに問わずハッシュタグ検索でヒットした画像や投稿の情報を取得できる。
ただしgraph apiは消費者アカウント(一般のアカウント)の情報に一切アクセスできない。つまりハッシュタグ検索でヒットする情報はビジネスアカウント(やクリエーターアカウント)の投稿のみである。
またハッシュタグ検索によりヒットした投稿の投稿者に関する情報も取得することはできない。
利用にはinstagramのビジネスアカウント、facebookページの登録、facebook開発者アカウントの登録、アプリの登録が必要である。graph apiの利用開始方法はインターネット上に情報が多数あるので、検索してほしい。
<おまけ>
デートスポットの収集には一般ユーザの投稿が最適であったが、不特定多数のユーザの投稿を収集することはできなかった。
また不適切な投稿を行うユーザをフィルタリングしようと試みたが、ハッシュタグ検索にてユーザ情報を収集することはできなかった。
最終的にはgraph apiを用いてビジネスアカウントの投稿を収集し、エクセルに集計するアプリとなった(当初の期待と比較して残念な結果となりましたが、成果物のリンクを記載しておきます)。
https://github.com/Shintaro-lab/instagram-hash-search-download.git
インスタで複数枚まとめて投稿された写真を一発でダウンロードする手法(instagram graph api)
instagramはinstagram graph apiというAPIが公開されており、ハッシュタグ検索等の検索や画像のダウンロードを自動化できる。
※APIの利用にはインスタグラムアカウント(ビジネスアカウント)、フェイスブックアカウント(ページ作成も)、facebook developerへの登録等が必要です(詳細はいろんな方がまとめているので、ググってみてください)。
ユーザの投稿の画像の枚数が1枚のみの場合は特別な考慮をせずにmedia_url(画像を参照するための固有のURL)が取得できるため、画像のダウンロードが容易である。

しかし複数枚画像がまとめて投稿されている場合(instagram graph apiでは、CAROUSEL_ALBUMと呼ぶ)、上記で取得を行うと各画像はidしか取得できない。

また下記のリファレンスに倣って画像を直接IDで取得しようと試みると、GraphMethodException(エラーコード:100、エラーサブコード:33)となって取得できない。
https://developers.facebook.com/docs/instagram-api/reference/ig-media
※IGメディアの取得はアクセストークンがユーザであるのに対しハッシュタグ検索はアクセストークンはページであり、使用可能なトークンが異なるからという可能性があるが、未検証。
しかしハッシュタグ検索のfieldsの指定の仕方を工夫すれば、一発で複数枚まとめて投稿された画像それぞれのmedia_urlを取得可能であるため、ここで共有する。
その方法とは、下記の通りchildren{media_url}という記載方法である。

上記のように指定すればmedia_typeがCAROUSEL_ALBUMであっても一発でmedia_urlが取得でき、media_urlに対して例えばpythonのrequestsライブラリのget等を行い、バイナリで書き出せば、画像をダウンロード可能なのである。
virtualboxのNATでもローカルマシンからのFTPは可能である
virtualboxには下記のような種類のネットワークを構成できる。
〇NAT
〇NAT Service
〇Bridged networking
〇Internal networking
〇Host-only networking
それぞれのネットワークの構成は下記の通りである(+は接続可能、-は接続不可)。

上記の中のNATはデフォルトで設定されるネットワークであるが、「ローカルマシンから仮想マシンへのFTP接続は不可となっているため、FTP通信を行うためにはHost-only networkingやBridged networkingを使わなければならない」という誤った解説をしている記事が大量に存在する。
したがって、本記事ではvirtualboxのNATでもローカルマシンからのFTPは可能であることを解説する。
結論から述べると、ローカルマシンから仮想マシンへのFTPはアクティブモードでは可能であるが、パッシブモードでは不可である。
仮想マシン側へ設定が必要なのは、下記の通りローカルマシン発の通信に対するポートフォワーディングのみである(仮想マシン発の通信はポートフォワーディングのルール設定は不要であるというのがvirtualboxのNATの本質である)。

以下で上記の事象を検証する。
まず検証用に仮想マシン上にtest.txtやa.txtを作成しておく。
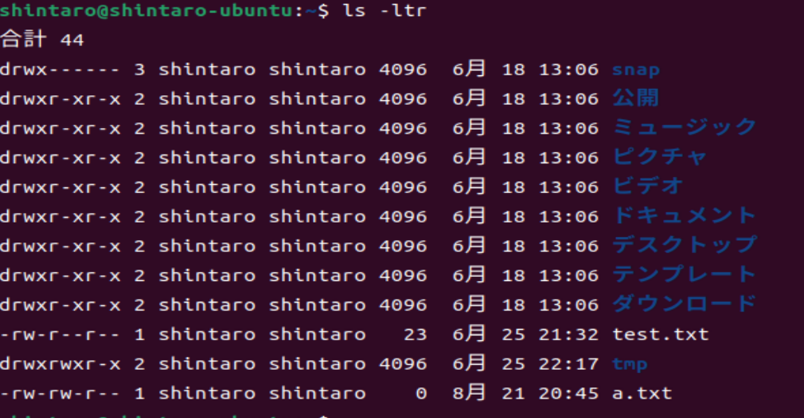
そして、ローカルマシンのWSL上からFTP接続を実施する。
172.26.192.1というのは、WLSネットワークのローカルマシンそのものを表している。
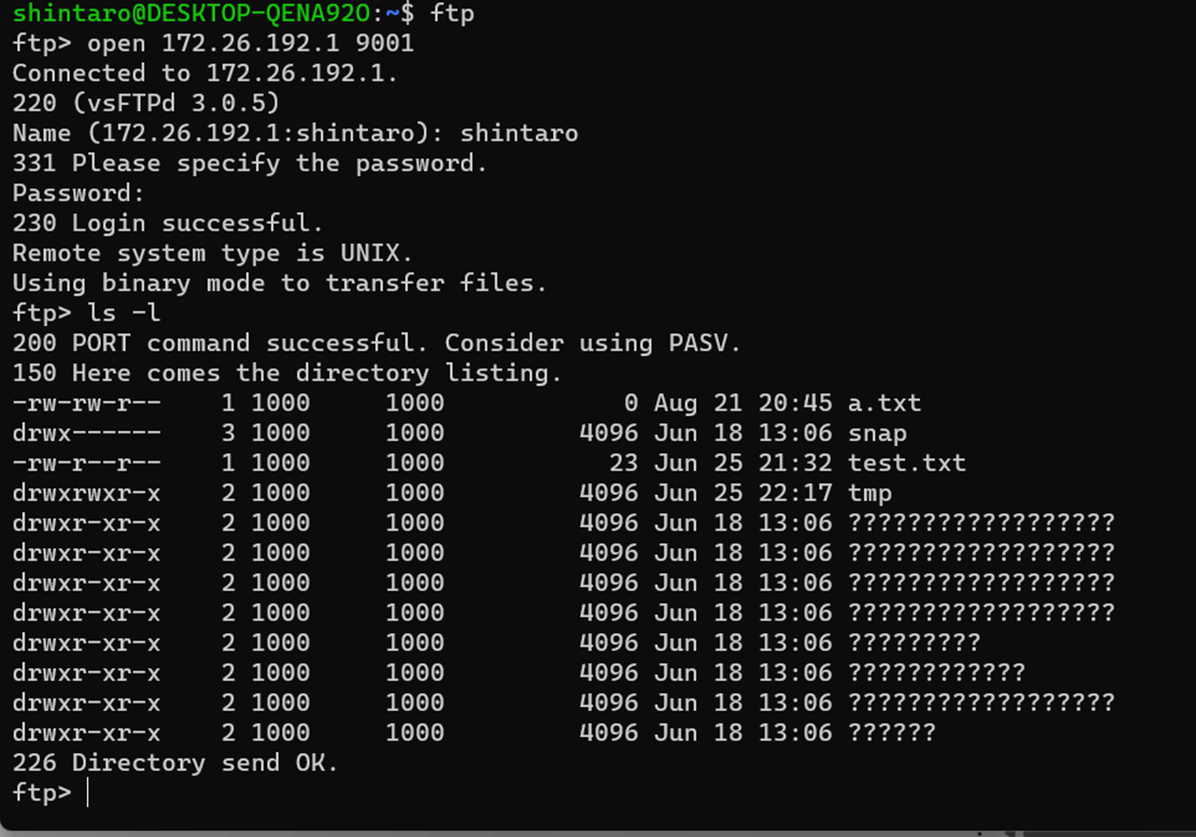
なおパッシブモードで接続するとFTPサーバ側、すなわち仮想マシンからデータ転送用ポートとIPが通知されるため、ローカルマシンに仮想マシンの実IPが通知されてしまう。
したがって、ローカルマシンには見えないIPアドレスに対してアクセスを行おうとするため、パッシブモードでは下記の通り拒否されてしまうのである。
![]()
なお扱いやすさという観点ではHost-only networkingが上回るため、上記の仕組みを理解した上でHost-only networkingを作成するのがベストと考えている。
障害対応でよく使うコマンド
障害対応時は時間的リミットによる焦りから冷静なコマンド検索ができず、必要なオプション等が見つからないことがある。またそもそもコマンドの存在を知らない・忘れている場合は、検索する術もない状態となってしまう。
インフラ系のエンジニアの方がまとめているサイトはいくつか見られたが、アプリ系・業務系のエンジニア向けのサイトがあまりないため、経験上よく使用するコマンド一覧を整理しておく。
■フォルダ移動
〇cd フォルダ名
おなじみのコマンド。解説は省略する。
〇ドライブ:(例d:)
windowsサーバで運用している場合に、他のドライブに移動する。
■ログ確認
〇ls -ltr ファイル名([a-b0-1]などで正規表現を利用可能。この場合はa~bまたは0~1)
ファイル名を表示するのがlsコマンド。lオプションは詳細、trで更新日が最新のものを一番下に表示する。最後に異常終了したものが一番ターミナルの下に出る方が便利なので、逆順で表示させる。
〇cat ファイル名
ファイルの中身を表示する。
■ファイルの退避・作成・削除
〇mkdir -p ディレクトリ名
ファイルを退避する用などにwrkフォルダを作成することがある。その際にディレクトリを作成できる。pオプションにより、パスで指定した場合も途中にそのフォルダがなければフォルダを作成できる。
〇cp -p 対象ファイル名 コピー先
本番ファイルなどをwrkフォルダに退避する際などに利用する。pオプションで属性も保持できるので必ずつける。
〇diff -s 対象ファイル① 対象ファイル②
ファイル間の差分を確認する。sオプションを同一の場合も同一である旨を表示してくれるため、コマンドの誤動作と区別ができる。
〇touch ファイル名(中身を入れたい時は、echo "文字列">ファイル名とする。)
ゼロバイトファイルを作成するときに利用する。
〇mv 元ファイル名 変更後ファイル名
リネームする際に利用する。コピーコマンドでも問題なし。
〇rm -i ファイル名(ディレクトリの際は、rm -ir ディレクトリ名)
ファイルやディレクトリを削除する際に利用する。削除は危険なコマンドであるため、必ずiオプションをつけ削除前に確認できるようにする。
〇tar -zcvf 圧縮ファイル名.gz 対象ファイル名(正規表現や*を利用する) --remove-files
大量ファイルを一度に削除したい場合は、tarで固めると便利である。念のためgz圧縮してローカルにバックアップしてから削除する。(--remove-filesを指定すると、tarで固めた後は該当ファイルを削除してくれる。)
■ファイル編集(vi)
〇[escキー]+:wq
保存して閉じる。
〇[escキー]+:q!
保存しないで閉じる。
〇h(左),l(右),j(下),k(上)
括弧に記載の方向へカーソルを移動する。
〇o
カーソルの下の行にテキスト追加。
〇a
カーソルの右にテキスト追加。
〇x
カーソルの文字削除。
〇数字+dd
数字で指定した行を削除。大量の行を削除するときに重宝。
〇/文字列
文字列を検索する。
〇:g/検索文字列/s//置換文字列/gc
文字列を置換する。cをつけているので、都度確認可能。
〇:set list(:set nolistで非表示。windowsの改行コードが^Mにならなければ、:e ++ff=unixも実施する)
改行コードを表示。
■文字コード・改行コード
〇file ファイル名
文字コードとファイル形式表示。
〇nkf --guess ファイル名
改行コードを表示。
〇sed 's/$/\r/g' 対象ファイル名 > 一時的なファイル名
LF(linux)からCRLF(windows)の改行コードへ変更する。一時的なファイル名に吐き出し、ワークから本番ディレクトリに戻すときにファイル名を変更する。
〇sed 's/\r//g' 対象ファイル名 > 一時的なファイル名
CRLF(windows)からLF(linux)へ改行コードを変更する。
■ファイル検索
〇grep -r 文字列 検索対象
検索対象の文字列を検索対象の中で検索する。rをつけることで、サブディレクトリも検索できる。
〇grep -rL 文字列 検索対象
検索文字列が合致しないファイル一覧を作成。
■圧縮ファイルの操作
〇tar -zcvf 圧縮後ファイル名.gz 対象
対象を圧縮する。
〇tar -zxvf 対象ファイル.gz
対象を解凍する。
〇zcat ファイル名(もしくは、tar -zxOf ファイル名)
解凍せずに、中身を表示。
■サーバの容量確認
〇df -h ディレクトリ
該当ディレクトリの容量を表示。空き容量不足でファイルが書き込めないときなどに使う。
■ファイル転送障害
〇ping 宛先 -c4
4回pingを送る。
〇ftp→open 宛先→bin(バイナリモード)→passive(デフォルトはパッシブモードなので、アクティブモードへ変更)
アクティブモード、かつバイナリで転送することが多いので、該当の設定にしてから対象ファイルの有無やput/getを行う。
■プロセス障害
〇ps aux | head -1
プロセスコマンドのヘッダを確認しておく。次のコマンドを打つ際、プロセスID等を間違えないようにする効果がある。
〇ps aux | grep サービス名
特定のサービスのプロセスIDを特定する。ハングアップ等でよく利用する。
〇kill プロセスID
特定のプロセスを強制停止させる。
今回は、障害対応で利用頻度の高いコマンドを整理してみました。
ほかにもよく使うコマンドがあれば、ぜひコメントください。
opensshの暗号アルゴリズムを確認するには、結局デバッグモードが一番という話
ファイル転送にもセキュアな接続が求められることが多い昨今、特にunix系のOSでよく使用されるフリーのソフトがopensshである。
ssh接続を行う際にまずkexやcipher等と呼ばれる暗号アルゴリズムについてクライアント・サーバ側でそれぞれ対応している一覧を提示しあい、双方で一致しているアルゴリズムの中で最もセキュアなものが選択される。
もし一致するアルゴリズムがない場合は、下記のようなエラーが発生し接続ができない。(つまり簡単にいうとサーバ同士の相性のようなものだ)
![]()
接続テストを実施するのはプロジェクトがある程度進んでからだったりすることもあり、事前に対応している暗号アルゴリズムを確認しておきリスクヘッジする必要があるのだ。
ぱっと思い当たるのはsshコマンドのQオプションであるが、このQオプションはあくまで対応可能な暗号アルゴリズムの一覧であり実際の有効/無効とは関係がないのである。

次に思いつくのは、/etc/ssh/ssh_config(サーバ側はsshd_config)の設定を確認するという方法であるが、デフォルトでは設定がコメントアウトされており、そのままの設定を利用しているユーザも多いのではないか。つまりこの確認でも要件を満たさない。
※設定をコメントアウトしている場合は、opensshのソースコード内でデフォルト値を定義しているため、ソースをいちいち読み解かないといけない。
![]()
仮にssh_configで設定している場合も、例えばRHEL8以上のバージョンを利用している場合は/etc/crypto-policies/back-endsに暗号化ポリシーを設定でき、暗号化ポリシーの設定が優先されてしまうので誤った判断を起こしやすい。
また、まれにopenssl ciphers -Vなどによりopensslの暗号アルゴリズムの抽出をもって確認ができたことにする人がいるが、opensshはopensslのcryptoのライブラリを確かに参照はしているがどの暗号アルゴリズムを使うかはあくまでopenssh側で定義しており、同一ではないので注意してほしい。
つまり、結局のところ一発で確認する手法はなく、sftpコマンドの-vvオプション(3段階までvをつけることが可能)などで実際に提示されている一覧を抽出するのがベストなのである。
EDINET APIを使ったデータ取得プログラムを書いてみた
中島聡さんの「結局、人生はアウトプットで決まる」という本を読んで感銘を受けたので、早速ブログを始めてみました。
初回はEDINET APIを使ったデータ取得プログラムを書いてみたので、分かったことをまとめてみようと思います。
そもそもEDINETとは、金融庁が運営している開示システムのことで主に有価証券報告書が取得可能なサイトのことです。
書類検索というタブを選ぶと、企業が開示したPDFやXBRLファイルを取得できます。
※XBRLというのは金融系のデータを開示するときのデータ形式のことです。イメージはHTMLに似ていて、<年齢>12</>のような形(本来は英語でタグ名が書いてあります)で開示されています。
GUIで画面からポチポチ取得もできるのですが大量にデータを重複なくダウンロードするのが大変だなと思っていたところ、金融庁がAPIを公開していることがわかったので早速プログラムを書いてみました。
※APIとはシステムの機能を外部から呼び出すためのインターフェースのことで、今回でいうと指定のURLにアクセスするとほしいPDFファイルがダウンロードできたりします。
指定のURLにリクエストを投げると、指定日付に開示されたデータのjson情報の一覧が返ってきます。
jsonデータから取得したい開示文書IDを抽出し、再度リクエストを投げるとPDFファイルやXBRLファイルがダウンロードできる仕組みでした。
今回はREST APIの王道であるpythonのrequestsを使ってプログラムを書きました。
ポイントは下記の2つです。
①REST APIの応答データのPDFやZIPファイルの内容はバイナリデータで返答されるので、レスポンスのcontentをバイナリ形式でファイルに書き出す必要がある。
※バイナリとは、テキストの反対で人間が読んでも直接は解読できない形式のデータのことをいいます。
②書類ダウンロードAPIのレスポンスは一部欠けていることがあるため、jsonには書き出さずstatus_codeを参照してエラーハンドリングした方がよい。
※レスポンスをjsonにdumpしようとすると、JSONDecodeError:Expecting Valueとなり抜け出せなくなりました。
その他で発見したことは、訂正有価証券報告書を開示するときは確認書の開示も義務付けられていますが、EDINETのGUIでは画面に確認書も表示されるものの検索結果の件数に記載の数字には含まれないということです(最初はGUIに合わせようと子ドキュメントも取得しようとしましたが、GUIの検索結果件数とAPIの取得件数が一致せずに1時間くらい悩みました。。。)。
ベータ版としてPDFのみ取得できるようにしました。XBRLの取得や取得エラーとなったファイルの再取得、環境変数の外部ファイル分離など、まだまだ改善していこうと思います。
実際に作成したプログラムはGithubに公開してみたので、興味があれば見てみてください。
https://github.com/Shintaro-lab/EDINET-API.git